Czym jest crawling i indeksowanie?
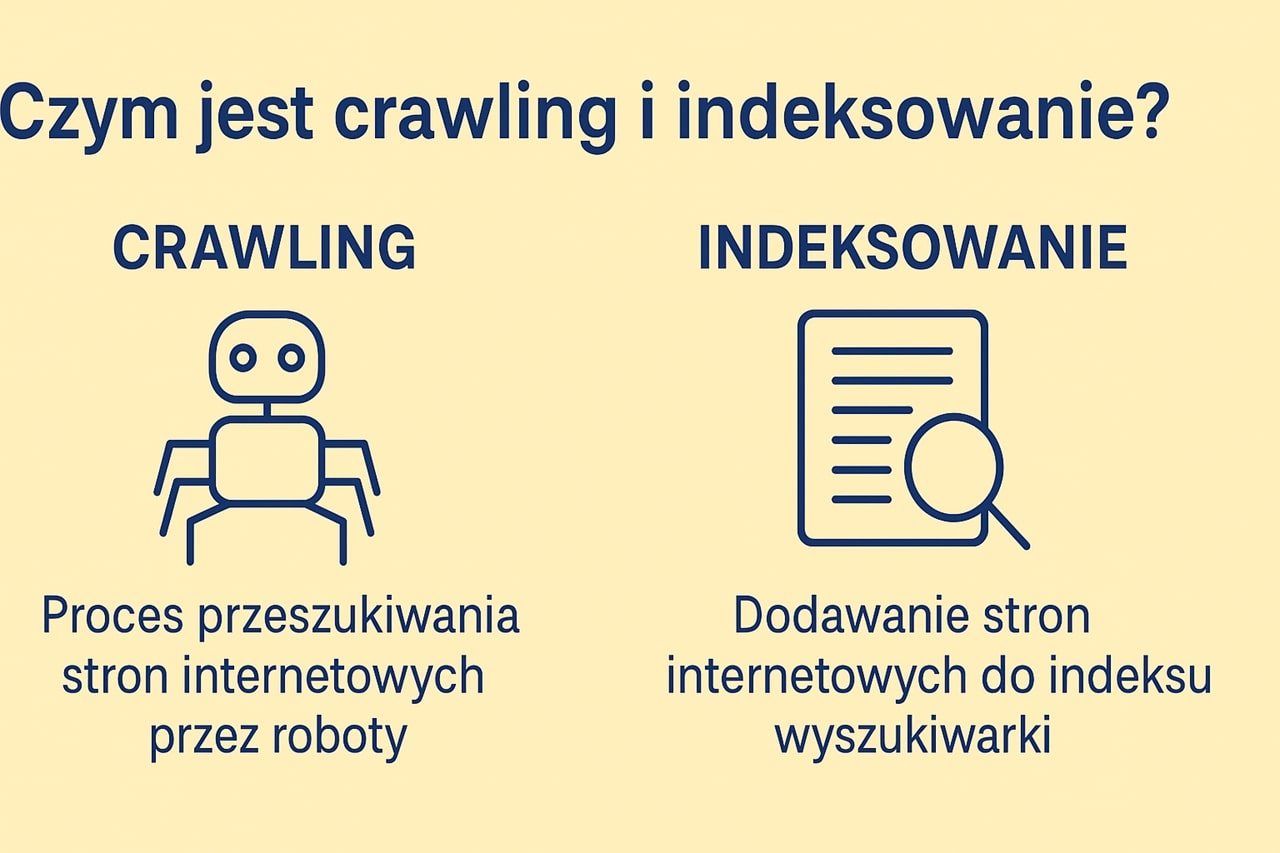
Kiedy wpisujesz zapytanie w wyszukiwarce Google, oczekujesz szybkich, trafnych odpowiedzi. Jednak niewielu użytkowników zdaje sobie sprawę z tego, jak ogromny i skomplikowany proces stoi za pozyskaniem tych wyników. Wszystko zaczyna się od dwóch fundamentalnych procesów: crawlingu (skanowania) i indeksowania.
To właśnie dzięki nim wyszukiwarka jest w stanie „znać” zawartość miliardów stron internetowych i wyświetlać najbardziej trafne wyniki w odpowiedzi na Twoje pytanie.
Czym jest crawling?
Definicja
Crawling (inaczej: skanowanie) to proces, w którym specjalne programy komputerowe – roboty indeksujące (np. Googlebot) – przemierzają internet, odwiedzając strony internetowe i zbierając z nich dane.
Jak działają roboty?
Roboty działają według określonych algorytmów:
- Zaczynają od listy znanych adresów URL (np. z poprzednich sesji lub zgłoszonych przez webmasterów).
- Odwiedzają każdą stronę, analizując jej treść, kod HTML, odnośniki wewnętrzne i zewnętrzne.
- Wykrywają nowe linki i dodają je do kolejki stron do odwiedzenia.
- Zwracają uwagę na zmiany – jeżeli dana strona uległa modyfikacji od ostatniej wizyty, robot ją ponownie przeskanuje.
Rodzaje robotów
- Googlebot – robot wyszukiwarki Google.
- Bingbot – robot Microsoftu.
- YandexBot, BaiduSpider – roboty wyszukiwarek z Rosji i Chin.
- Mobile/Smartphone bots – dedykowane roboty mobilne skanujące wersje mobilne stron.
Częstotliwość skanowania
Częstotliwość odwiedzin zależy od:
- Autorytetu strony (PageRank, Domain Authority),
- Częstotliwości aktualizacji treści,
- Szybkości ładowania strony,
- Responsywności serwera,
- Zawartości pliku robots.txt i nagłówków HTTP.
Co to jest indeksowanie?
Definicja
Indeksowanie to etap następujący po crawlowaniu. Polega na tym, że wyszukiwarka analizuje zebrane dane i zapisuje je w swoim indeksie – olbrzymiej, stale aktualizowanej bazie danych.
Co trafia do indeksu?
- Tekst widoczny na stronie,
- Znaczniki semantyczne (nagłówki H1, H2, meta description, alt text),
- Struktura dokumentu HTML,
- Informacje o linkach (anchor text, destination URL),
- Dane strukturalne (schema.org),
- Niektóre elementy multimedialne (jeśli są odpowiednio opisane),
- Czasem także zawartość JavaScript (jeśli strona pozwala na tzw. renderowanie po stronie klienta).
Co NIE trafia do indeksu?
- Zawartość zablokowana przez robots.txt,
- Strony oznaczone jako „noindex”,
- Treści ukryte za logowaniem,
- Nieczytelne lub uszkodzone strony,
- Duplicate content (duplikaty).
Jak crawling i indeksowanie wpływają na SEO?
Dla właściciela strony internetowej te procesy są kluczowe z punktu widzenia widoczności w wyszukiwarkach. Jeśli robot nie zeskanuje Twojej strony lub nie zindeksuje jej poprawnie – nie pojawi się ona w wynikach wyszukiwania.
Najczęstsze błędy SEO związane z crawlingiem i indeksowaniem
- Błędnie skonfigurowany robots.txt, który blokuje ważne zasoby.
- Użycie noindex na stronach, które powinny być widoczne.
- Brak linków wewnętrznych prowadzących do nowych treści.
- Nadmiar zduplikowanych treści (np. z powodu parametrów URL).
- Wolny czas ładowania strony (niska wydajność = niższa częstotliwość skanowania).
- Brak mapy witryny (sitemap.xml).
Jak sprawdzić, czy strona jest crawlowana i indeksowana?
Narzędzia diagnostyczne
- Google Search Console – pokazuje, które strony zostały zindeksowane, jakie błędy napotkał robot, czy występują problemy z renderowaniem.
- Bing Webmaster Tools – analogiczne narzędzie od Microsoftu.
- Polecenie „site:” w Google – np. site:twojadomena.pl pozwala sprawdzić, co jest w indeksie.
- Logi serwera – umożliwiają analizę ruchu botów.
- Crawler tools (np. Screaming Frog, Sitebulb) – symulują działanie robotów.
Mapa witryny (sitemap.xml) i robots.txt – dwa pliki, które kontrolują cały proces
sitemap.xml
- Zawiera listę stron do indeksowania,
- Może zawierać priorytety i daty ostatniej modyfikacji,
- Ułatwia robotom odnalezienie i zaindeksowanie nowych podstron.
robots.txt
- Plik umieszczany w głównym katalogu domeny,
- Pozwala blokować dostęp do określonych zasobów (np. /admin/, /cart/),
- Nie gwarantuje całkowitej prywatności – to raczej „prośba”, nie twarda blokada.
Indeksowanie a renderowanie – jak wyszukiwarka „widzi” Twoją stronę?
Dawniej Google analizował jedynie HTML. Dziś:
- Renderuje również JavaScript (ale z opóźnieniem),
- Sprawdza użyteczność mobilną (mobile-first indexing),
- Bada Core Web Vitals (np. LCP, FID, CLS),
- Może analizować dane strukturalne i interaktywność strony.
To oznacza, że nawet po crawlowaniu i zindeksowaniu – rendering może zadecydować, czy Twoja strona zostanie dobrze oceniona.
Jak przyspieszyć indeksację strony?
- Dodaj stronę do sitemap.xml,
- Zgłoś URL ręcznie przez Search Console (opcja „Sprawdź URL”),
- Wprowadź linki wewnętrzne z już zindeksowanych podstron,
- Promuj nową stronę (np. linki zewnętrzne),
- Dbaj o wydajność techniczną i czytelność kodu.
Czy każda strona powinna być zindeksowana?
Nie. Czasem warto świadomie blokować indeksowanie:
- Stron administracyjnych,
- Koszyków zakupowych,
- Wersji drukowanych,
- Duplikatów treści (np. tagi, archiwa),
- Treści testowych lub roboczych.
Podsumowanie
Crawling i indeksowanie to fundamenty działania każdej wyszukiwarki internetowej. Zrozumienie ich zasad jest niezbędne nie tylko dla specjalistów SEO, ale dla każdego, kto prowadzi stronę internetową i chce zwiększyć jej widoczność.
Dobrze zoptymalizowana witryna to taka, którą roboty:
- łatwo znajdują (dzięki sitemap i linkom),
- bez przeszkód skanują (brak blokad i błędów),
- poprawnie indeksują (czytelna struktura, wartościowa treść).
Świadoma kontrola nad tymi procesami to droga do lepszych pozycji w wynikach wyszukiwania, większego ruchu i większej skuteczności online.
FAQ – Crawling i indeksowanie
1. Czy każda strona w internecie jest indeksowana przez Google?
Nie każda strona internetowa trafia do indeksu Google. Aby strona została zaindeksowana, musi być publicznie dostępna, nie może być zablokowana w pliku robots.txt, nie może zawierać tagu noindex, a także powinna mieć odpowiednią jakość. Wyszukiwarka omija treści ukryte za logowaniem, duplikaty oraz strony, które są zbyt ubogie w wartość merytoryczną lub zawierają istotne błędy techniczne.
2. Jak sprawdzić, czy moja strona została zaindeksowana?
Aby sprawdzić, czy strona jest zaindeksowana, można użyć polecenia site:twojadomena.pl w wyszukiwarce Google. Dzięki temu zobaczysz, które podstrony znajdują się w indeksie. Bardziej zaawansowaną analizę zapewnia Google Search Console, gdzie dostępne są szczegółowe informacje o statusie indeksowania, błędach i ewentualnych problemach z renderowaniem.
3. Czy plik robots.txt całkowicie blokuje dostęp do strony?
Plik robots.txt pełni funkcję instrukcji dla robotów indeksujących, ale nie jest narzędziem do całkowitej blokady dostępu. To raczej sugestia – większość robotów ją respektuje, ale nie jest to zabezpieczenie przed indeksacją lub wyciekiem danych. Jeśli chcesz mieć pewność, że dana strona nie zostanie zaindeksowana, musisz dodatkowo użyć znacznika noindex lub zabezpieczyć ją hasłem.
4. Co to jest sitemap.xml i czy jest obowiązkowa?
Sitemap.xml to specjalny plik, który zawiera listę wszystkich istotnych stron w obrębie witryny, wraz z informacjami o dacie ostatniej aktualizacji czy priorytecie. Nie jest wymagany przez wyszukiwarki, ale bardzo pomaga w przyspieszeniu indeksowania, zwłaszcza w przypadku dużych serwisów, sklepów internetowych lub witryn z dynamicznie generowaną treścią.
5. Dlaczego moja strona została zeskanowana, ale nie zindeksowana?
Zdarza się, że strona zostaje przeskanowana przez robota, ale nie trafia do indeksu. Może to wynikać z użycia tagu noindex, zduplikowanej lub niskiej jakości treści, błędów technicznych, problemów z renderowaniem lub tego, że algorytm Google uzna stronę za niewystarczająco wartościową dla użytkownika. W takim przypadku strona jest znana wyszukiwarce, ale nie pojawia się w wynikach wyszukiwania.
6. Jak długo trwa indeksowanie nowej strony?
Czas indeksowania nowej strony jest zmienny i zależy od wielu czynników. Może zająć od kilku minut do kilku tygodni. Wpływają na to m.in. autorytet domeny, liczba i jakość linków prowadzących do strony, częstotliwość aktualizacji treści, obecność strony w mapie witryny oraz to, czy została ona ręcznie zgłoszona do indeksacji przez Google Search Console.
7. Czy usunięcie strony z indeksu wpływa na pozycjonowanie całej witryny?
Usunięcie jednej strony z indeksu nie wpływa bezpośrednio na pozycję innych podstron. Jednak jeśli witryna zawiera wiele niskiej jakości lub błędnych stron, to algorytmy Google mogą ocenić ją jako całość mniej przychylnie. W praktyce oznacza to, że nadmiar zbędnych lub słabych stron może zaszkodzić ogólnemu SEO witryny.
8. Czy Googlebot widzi wersję mobilną czy desktopową mojej strony?
Obecnie Google stosuje podejście mobile-first indexing, co oznacza, że robot Googlebot analizuje w pierwszej kolejności wersję mobilną strony. Jeśli witryna w wersji mobilnej różni się od desktopowej, to właśnie ta mobilna będzie brana pod uwagę przy ocenie treści, struktury i użyteczności strony.
9. Czy mogę samodzielnie wymusić ponowne indeksowanie strony?
Tak, istnieje możliwość ręcznego zgłoszenia strony do ponownego zindeksowania. Można to zrobić za pomocą Google Search Console, korzystając z funkcji „Sprawdź URL”, a następnie klikając „Poproś o zaindeksowanie”. Warto jednak pamiętać, że Google nie gwarantuje natychmiastowej reakcji i zastrzega sobie prawo do uznaniowego indeksowania.
10. Jak często Google odwiedza moją stronę?
Częstotliwość odwiedzin przez roboty indeksujące zależy od wielu czynników. Duże i często aktualizowane serwisy mogą być odwiedzane kilka razy dziennie, podczas gdy mniejsze, statyczne strony – raz na kilka tygodni. W Google Search Console, w zakładce Statystyki indeksowania, można sprawdzić częstotliwość żądań i liczbę pobieranych stron w danym okresie.